
I am a Ph.D. candidate in Computer Science at the University of Waterloo and the Vector Institute, advised by Prof. Pascal Poupart. I am also a research intern at Vijil, advised by Prof. Tim G. J. Rudner, and a research member of the Normativity Lab, where I work with Prof. Gillian Hadfield.
My research centers on cooperative and safe agentic AI, spanning reinforcement learning, large language models, mechanism design, information design, and game theory. I am especially interested in developing mechanisms and algorithms that foster cooperation, trustworthiness, and safety in mixed-motive multi-agent systems, including both RL-based and generative agents.
You can reach me at shuhui [dot] zhu [at] uwaterloo [dot] ca.
News
- August 2026: I will present our paper Talk, Judge, Cooperate: Gossip-Driven Indirect Reciprocity in Self-Interested LLM Agents at the Cooperative AI Summer School 2026 in Toronto.
- July 2026: I will present Talk, Judge, Cooperate: Gossip-Driven Indirect Reciprocity in Self-Interested LLM Agents at ICML 2026 in Seoul.
- June 2026: Joined Vijil as an assistant applied scientist, supervised by Prof. Tim G. J. Rudner, researching and developing methods to improve the safety and trustworthiness of AI agents.
- May 2026: Our paper Talk, Judge, Cooperate: Gossip-Driven Indirect Reciprocity in Self-Interested LLM Agents was accepted to The 43rd International Conference on Machine Learning (ICML 2026).
- August 2025: I will be at RLC 2025 Workshop on Coordination and Cooperation in Multi-Agent Reinforcement Learning presenting our paper Learning to Negotiate via Voluntary Commitment.
- July 2025: I will be at EC’25 Workshop on Swap Regret and Strategic Learning and Cooperative AI Summer School 2025 presenting our paper Learning to Negotiate via Voluntary Commitment.
- January 2025: Our paper Learning to Negotiate via Voluntary Commitment was accepted to The 28th International Conference on Artificial Intelligence and Statistics (AISTATS, 2025).
- August 2024: Joined the Normativity Lab as a research assistant at the University of Toronto and the Schwartz Reisman Institute, supervised by Prof. Gillian Hadfield.
- July 2024: Attended CIFAR Deep Learning + Reinforcement Learning Summer School.
- January 2022: Started Ph.D. at the David R. Cheriton School of Computer Science, University of Waterloo and the Vector Institute, supervised by Prof. Pascal Poupart.
- May 2021: Started internship at PerkinElmer as a Machine Learning Engineer.
- September 2020: Started MMath in Computational Mathematics at the University of Waterloo, supervised by Prof. Hans De Sterck and Prof. Jun Liu.
Publications
Talk, Judge, Cooperate: Gossip-Driven Indirect Reciprocity in Self-Interested LLM Agents
Shuhui Zhu, Yue Lin, Shriya Kaistha, Wenhao Li, Baoxiang Wang, Hongyuan Zha, Gillian K Hadfield, Pascal Poupart
ICML, 2026
Paper | Code | Talk | Poster
We introduce public gossip as a decentralized reputation mechanism that enables self-interested LLM agents to cooperate in mixed-motive settings. Building on this idea, our ALIGN framework uses hierarchical gossip to assess trustworthiness, sustain reciprocity, and reliably exclude defectors.
Learning to Negotiate via Voluntary Commitment
Shuhui Zhu, Baoxiang Wang, Sriram Ganapathi Subramanian, Pascal Poupart
AISTATS, 2025
Paper | Code | Talk | Poster
We present a novel framework where RL agents can propose and voluntarily commit to actions in strategic interactions, improving cooperation among self-interested agents in challenging mixed-motive environments.
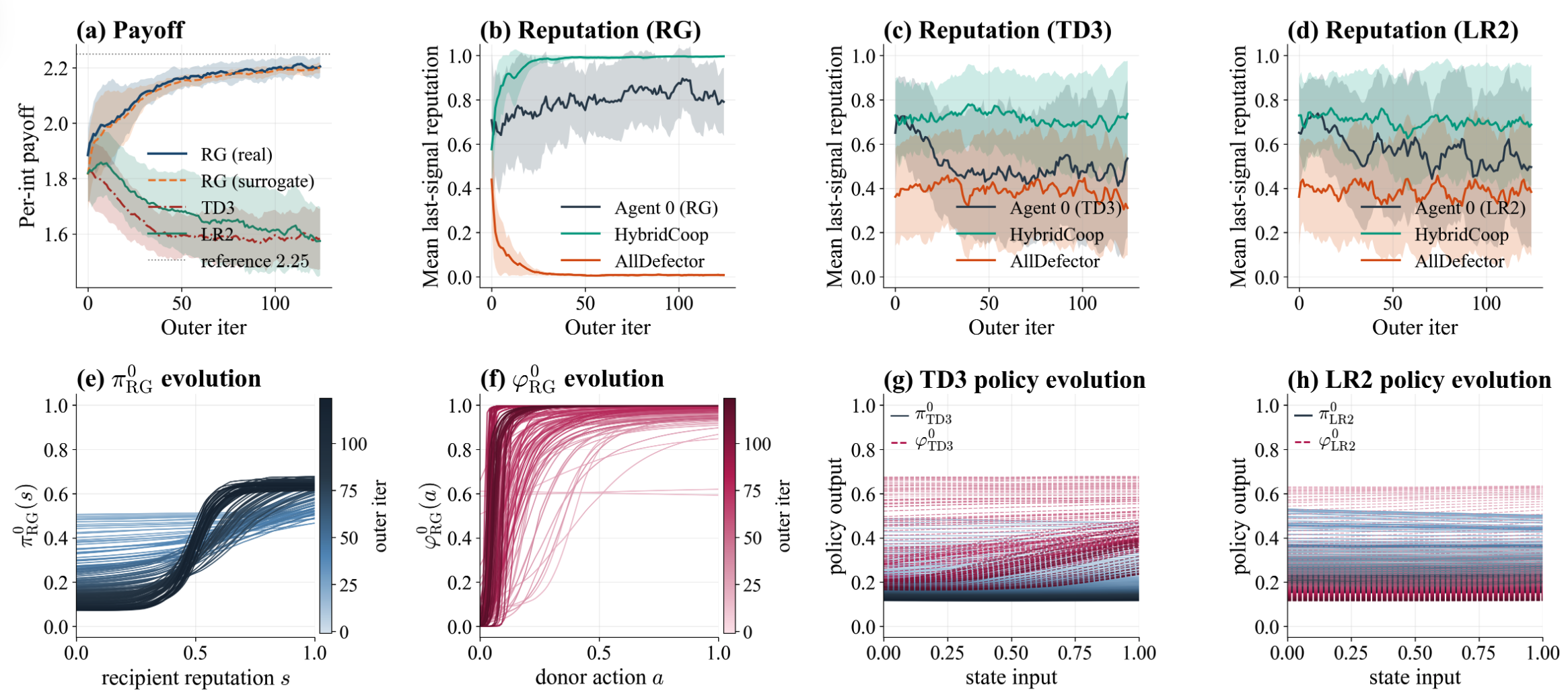
The Reciprocity Gradient
Yue Lin, Pascal Poupart, Shuhui Zhu, Dan Qiao, Wenhao Li, Yuan Liu, Hongyuan Zha, Baoxiang Wang
Working Paper
Paper
We introduce the reciprocity gradient, a novel method for learning cooperative policies in multi-agent environments by explicitly backpropagating reward gradients through private estimators of opponents' policies, enabling agents to account for the complex influence of their actions on others' reputations and future rewards without relying on intrinsic rewards or reward shaping.

Policy-Conditioned Policies for Multi-Agent Task Solving
Yue Lin, Shuhui Zhu, Wenhao Li, Ang Li, Dan Qiao, Pascal Poupart, Hongyuan Zha, Baoxiang Wang
Working Paper
Paper
We introduce Policy-Conditioned Policies, a paradigm that represents multi-agent strategies as human-interpretable code and leverages Large Language Models to iteratively synthesize and optimize these programmatic policies for adaptive task solving.
Information Bargaining: Bilateral Commitment in Bayesian Persuasion
Yue Lin, Shuhui Zhu, William A Cunningham, Wenhao Li, Pascal Poupart, Hongyuan Zha, Baoxiang Wang
Working Paper
Paper
This paper reframes Bayesian persuasion as an information bargaining problem to address its complexity in long-term interactions. Unlike one-sided commitment models, the proposed framework enables fairer and more efficient cooperation by balancing the sender's and receiver's roles. Empirical validation using LLMs confirms the framework’s predictions.
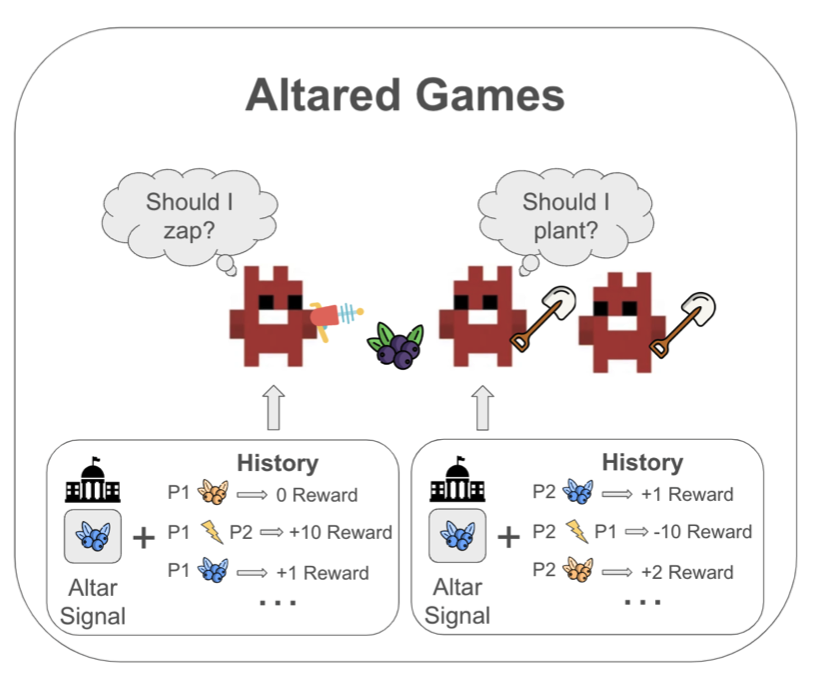
Altared Environments: The Role of Normative Infrastructure in AI Alignment
Rakshit Trivedi, Nikhil Chandak, Andrei Ioan Muresanu, Shuhui Zhu, Atrisha Sarkar, Joel Z Leibo, Dylan Hadfield-Menell, Gillian K Hadfield
Submitted to ICLR, 2024
Paper
We propose Altared Games, a novel Markov game framework integrating a classification institution to enable AI agents to adapt to dynamic norms, demonstrating its effectiveness in enhancing cooperation and social welfare in multi-agent reinforcement learning environments.
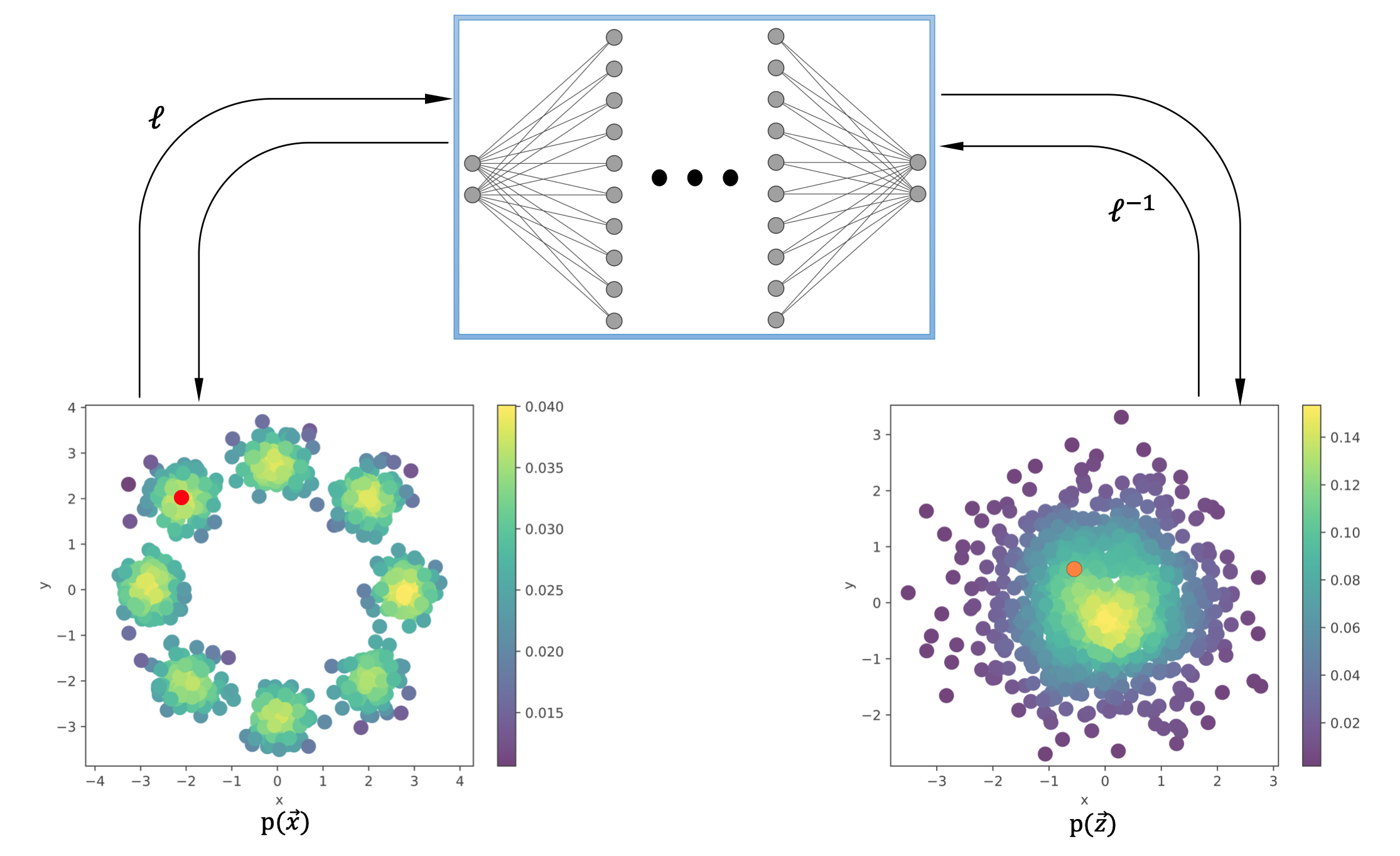
Spline Parameterization for Continuous Normalizing Flows
Shuhui Zhu
Master's Thesis, 2021
Thesis
I develop a Spline-based parameterization method for Continuous Normalizing Flows using Neural ODEs, formulating the problem as an optimal control task to efficiently learn time-dependent patterns while reducing computational cost and maintaining accuracy.